작성자 : porowl
추천 : 2
조회수 : 1325회
댓글수 : 6개
등록시간 : 2017/05/10 13:53:29
<더 플랜>에 출현하셨던 교수님들께서
노인 가설을 반박하는 자료를 며칠 전에 올리셨더군요.
최근 저의 글/덧글에서의 노인 가설 반박 논리처럼,
여기서도 노인 가설을 전제했을 때는
존재하는 데이터가 설명 불가능한 모순적 결과가 나타납니다.
귀류법적 논증을 통해 노인 가설은 거짓임을 알 수 있고,
대선들의 비정상적 K값들이
노령층때문이다는 여론을 무작정 형성하는 것은 위험하다고 생각합니다.
아래는 프로젝트 부 사이트에 올라온 "18 대 대선 데이타에서 나온 K=1.5 에 대한 보충 설명"
---------------------------------------------------------------------------------
18 대 대선 데이타에서 나온 K=1.5 에 대한 보충 설명
작성자: 김현승, 전희경, 현화신
<더 플랜>에서 제기한 K 값에 대한 관심에 다시 한 번 감사드립니다. 노령층에 의해 높아지는 미분류표 비율로 18대 대선 결과를 설명할 수 있다고 하는 가설이 (이하 “노령층 가설”) 있어서, 이 가설이 가지는 한계를 확률을 이용하여 설명하고자 합니다. 다섯 가지 자료를 통해 <더플랜> 시나리오는 전국뿐만 아니라 각 지역을 모두 잘 설명하는 것을 보이는 반면에, 노령층 가설은 각 지역에 대한 설명을 제대로 하지 못하는 것을 실제 데이타와 비교하여 보이겠습니다.
1. 선거 데이타 수집 과정 (신뢰도)
본 연구에 사용된 데이타는 모두 선관위 자료 공개 청구를 통해 얻은 공식적인 자료로서 각 지역의 개표상황표를 정리한 것입니다. 이러한 데이타들을 프로젝트 부 웹사이트에 엑셀 화일 또는 사진 화일로 업로드를 하여 공개하였으므로, 데이타에 대해 문의할 것이 있으면 직접 선관위에 하셔도 되겠습니다. 첨부된 화일의 부록 A에 각 개표 지역에서 나온 대선 결과 4가지 득표수와 3가지 상대적 비율을 보였습니다. 특히KU & KC값의 차이에 주목하기 바랍니다 (“18대 대선 데이타 & 시뮬레이션 결과_251 개표지역 (May01_2017).pdf” 참고),
2. 시뮬레이션 과정
시뮬레이션의 목적은 전적으로K=1.5와 확률만 이용하여, 각 지역 분류표와 미분류표에서 나온 후보1과 후보2 각각의 득표율 네 가지를 재구성하려는 것이었습니다. 먼저 첫 단계에서 가상 투표지를 최대한 실제 투표 결과와 가깝게 만들었고, 두번째 단계에서는 이 투표지를 전자개표기가 읽으면서 분류하는 것처럼 프로그램하였습니다 (통계 소프트웨어 R 사용).
부록 B에 (18대 대선 데이타 & 시뮬레이션 결과_251 개표지역 (May01_2017).pdf) 시뮬레이션에 필요한 투표수 네 가지와 (아래 표 참고) 확률들에 대한 정의가 있습니다. 부록 C에는 시뮬레이션 결과가 실제 18대 대선 득표율과 쉽게 비교될 수 있도록 정리되어 있습니다. 부록 D에는 가상 투표지 만드는 R코드를 공개하였고, 나머지 부분을 공개하지 못한 점에 대해 양해를 구합니다. 나중에 기회가 있을 것입니다.
| 번호 | 투표수 | 총 미분류표 | 박 분류 | 문 분류 |
| 1 | 124,376 | 4,355 | 79,489 | 40,132 |
| 2 | 17,731 | 1,528 | 10,904 | 5,229 |
| 3 | 51,423 | 1,725 | 32,984 | 16,577 |
| 4 | 41,558 | 1,692 | 26,514 | 13,053 |
| 5 | 45,439 | 1,341 | 27,639 | 16,323 |
여기에서 시뮬레이션에 필요한 확률들은 모두 K=1.5 만 이용하여 계산하였고, 무효표는 각 지역의 미분류율의 10%로 모든 지역에 똑 같이 적용하였음을 알립니다. 따라서 시뮬레이션 결과와 18대 대선 득표율이 비슷하게 나온 사실은 K=1.5 만 이용한 시나리오가 18대 대선을 잘 설명함을 뜻하는 것입니다. 거듭 강조하지만, 사용한 시나리오는 대선 결과를 설명하는 한 가지 방법일뿐 원인 규명까지 하지는 못함을 밝힙니다. 선관위만이 가지고 있는 자료 분석을 통해 원인 규명을 할 수 있다고 판단합니다.
3. 각 개표 지역 후보1 과 후보2 의 분류표와 미분류표 득표수 예상값 계산 과정
시뮬레이션을 하지 않아도, 각 개표 지역의 분류표와 미분류표에서 나온 후보1과 후보2 각각의 득표수과 득표율, 그리고 무효표까지 예상할 수 있는 방법이 있습니다. 바로 확률을 이용한 기대값을 계산하는 것입니다. 첨부된 Excel file을 (“K_Election_2012_Prediction‐by‐K1.5_All‐251‐districts.xlsx”) 참고하시기 바랍니다.
엑셀 화일에 이미 계산법이 입력이 되어 있어서, 대선 자료인 Columns A~V까지 copy 해서Columns AB~AV 에 paste를 하면 자동으로 예상값들이 나타나는 것을 볼 수 있습니다. 관심있는 지역의 선거 자료를 가지고 직접 실험할 수 있습니다.
4. 50 대 미만/이상 투표자들의 표가 미분류로 갈 확률 계산
첫째, 아래와 같이 기호를 사용하고 계산은 대부분 유효 수자 세 개를 사용했습니다.
둘째, 연령에 따른 확률을 계산하려면 대선 결과 이외에 연령별 투표율과 연령별 지지율이 필요합니다.
<자료1> 후보별 득표율과 미분류 비율 (대선 자료, 신뢰도 높음)
Pr (P) = Pr (P ∩ C) + Pr (P∩ U) = Pr (P|C) Pr(C) + Pr (P|U) Pr (U)= 0.515 * 0.963 + 0.528 * 0.03 ≈ 0.515
Pr (M) = Pr (M ∩ C) + Pr (M ∩ U) = 0.482 *0.963 + 0.358 *0.037 ≈ 0.477
| C (분류표), 96.3% | U (미분류표), 3.7% | 합계 (기타 후보, 무효표 제외) | |
| P | P1 =P ∩ C, (51.5%) | P2 =P ∩ U, (52.8%) | 51.5% |
| M | M1 = M ∩ C, (48.2%) | M2= M ∩ U, (35.8%) | 47.7% |
| 합계 | 99.7% | 88.6% | 99.2% |
그런데 미분류표에서 나온 후보1과 후보2의 합이 100%가 되지 않으므로 다른 후보들에게 간 미분류표와 무효표들을 제외한 득표율을 계산하면 아래와 같은 결과가 나옵니다 (adjusted rates).
| C (분류표), 96.3% | U (미분류표), 3.7% | |
| P | 51.5/(51.5+48.2)=51.7% | 52.8/(52.8+35.8)=59.6% |
| M | 48.2/(51.5+48.2)=48.3% | 35.8/(52.8+35.8)=40.4% |
| 합계 | 100% | 100% |
<자료 2> 연령별 투표율 (선관위자료, 신뢰도 있음)
| 연령대 | 비율 |
| A (50대 이상) | 43.7% |
| B (50대 미만) | 56.3% |
<자료3> 연령별 지지율 (방송 3 사 출구조사, 신뢰도 확인되지 않음)
| 연령대 | 후보 1 | 후보 2 | 합계 | ||
| A (50대 이상) | 68% | 32% | 100% | Pr (P|A) = 0.68 | Pr (M|A) = 0.32 |
| B (50대 미만) | 37% | 63% | 100% | Pr (P|B) = 0.37 | Pr (M|B) = 0.63 |
<자료 4> 알려지지 않은 확률 :
| C (분류표) | U( 미분류표) | |||
| A (50대 이상) | 1‐q | q | Pr (U|A) = q Pr (C|A) = 1‐q | 0< q <1, q ≠ 0 & q≠1 |
| B (50대 미만) | 1‐r | r | Pr (U|B) = r Pr (C|B) = 1‐r | 0< r <1, r ≠ 0 & r≠1 |
Q1. 50대 이상/미만 연령층의 표가 미분류 될 확률?
50대 이상 연령층의 표가 미분류표가 될 확률 Pr (U|A)=q 라 하고,
50대 미만 연령층의 표가 미분류표가 될 확률Pr (U|B)=r 라 합니다.
앞으로 계산 하는 확률들은q & r을 구하기 위한 과정입니다.
Q2. 미분류에서 나온 후보 1 의 표가 50대 이상에서 나왔을 확률, Pr (A|P2) ?
(1) Pr (P2) = Pr (P∩ U) = Pr (P|U) * Pr (U) = 0.596 *0.037
(2) Pr (P2|A) = Pr (P∩U |A)
= Pr (P|A) *Pr (U|A) (why? P & U are conditionally independent given A)
= 0.68 *q
(3) Pr (A∩P2) = Pr (P2|A) *Pr (A) = 0.68*q *0.437
(4) Pr (A|P2) = 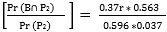 = 13.5*q
= 13.5*q
(5) 0 < 13.5*q <1 (확률이므로), q < 1/ 13.5 = 0.07. 따라서 q <7%
Q3. 미분류에서 나온 후보 2 표가 50 대 이상에서 나왔을 확률, Pr (A|M2) ?
(6) Pr (M2) = Pr (M∩ U) = Pr (M|U) * Pr (U) = 0.404 *0.037
(7) Pr (M2|A) = Pr (M∩ U|A) = Pr (M|A) *Pr (U|A) = 0.32 *q
(8) Pr (A∩M2) = Pr (M2|A) *Pr (A) = 0.32*q *0.437
(9) Pr (A|M2) = 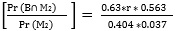 = 9.4*q
= 9.4*q
(10) 0 < 9.4*q <1 (확률이므로), q < 1/ 9.4 = 0.106. 따라서 q < 11%
(5) & (10)에서 50대 이상의 표가 미분류로 갈 확률은 최대 7%가 됩니다: q < 7 %.
주의: <자료 2 & 3>에 따라 이 수치는 달라질 수 있습니다.
Q4. 미분류에서 나온 후보 1 표가 50 대 미만에서 나왔을 확률, Pr (B|P2) ?
(11) Pr (P2|B) = Pr (P∩U |B) = Pr (P|B) *Pr (U|B) = 0.37 *r
(12) Pr (B∩P2) = Pr (P2|B) *Pr (B) = 0.37*r *0.563
(13) Pr (B|P2) = 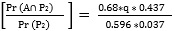 = 9.45r
= 9.45r
(14) 0 < 9.45*r <1 (확률이므로), r < 1/ 9.45 = 0.106 따라서 r < 11%.
Q5. 미분류에서 나온 후보 2 표가 50 대 미만에서 나왔을 확률, Pr (B|M2) ?
(15) Pr (M2|B) = Pr (M∩ U|B) = Pr (M|B) *Pr (U|B) = 0.63 *r
(16) Pr (B∩M2) = Pr (M2|B) *Pr (B) = 0.63*r *0.563
(17) Pr (B|M2) = 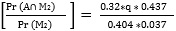 = 23.7*r
= 23.7*r
(18) 0 < 23.7*r <1 (확률이므로), r < 1/ 23.7 = 0.0422. 따라서 r < 4%.
(14) & (18)에서 50대 미만의 표가 미분류로 갈 확률은 최대 4%가 됩니다: r < 4%.
이제부터 q & r 의 값을 계산하기 위한 확률 방정식을 만듭니다.
(19) Pr(P2) = Pr (P2|A) Pr(A) + Pr (P2|B) Pr(B) = 0.68q*0.437+0.37r*0.563 = 0.297q+0.208r
(20) Pr(P2) = Pr (P∩ U) = Pr (P|U) * Pr (U) = 0.596*0.037 =0.022
따라서 0.297q+0.208r = 0.022. (*)
(21) Pr(M2) = Pr (M2|A) Pr(A) + Pr (M2|B) Pr(B) = 0.32q*0.437+0.63r*0.563 = 0.140q+0.355r
(22) Pr (M2) = Pr (M∩ U) = Pr (M|U) * Pr (U) = 0.404 *0.037 = 0.0149
따라서 0.140q+0.355r = 0.015. (**)
(*) & (**)는 2원 1차 방정식 2개 이므로 해를 구할 수 있습니다.
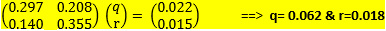
이번에는q & r의 값을 구하는데 이용할 수 있는 좀더 간단한 확률 방정식을 만들어 계산합니다.
(23) Pr (A|P2)+ Pr(B|P2) =1 ==> 13.5*q+9.45*r=1
(24) Pr (A|M2)+ Pr(B|M2) =1 ==> 9.36*q+23.7*r=1

q= 0.062 ===> Pr(U|A), 즉 50대 이상 연령층의 표가 미분류표가 될 확률이 6.2%.
r= 0.018 ===> Pr (U|B), 즉 50대 미만 연령층의 표가 미분류표가 될 확률이 1.8%.
주의: <자료2 & 3>에 따라 이 수치는 달라질 수 있습니다.
따라서 q/r = 3.4, 즉 50 대 이상에서 50대 미만보다 미분류표가 3.4배 정도 많이 발생했다는 것을 18대 대선 결과가 보여주었습니다. 그런데 이 것은 전국 모두를 합한 데이타에서 나온 것으로, 이 확률값들로 18대 대선 251 지역을 각각 설명할 수 있는지는 의문입니다. 아래에 있는 5번째 자료에서 좀더 분석하겠습니다.
5. 251개표 지역 각각에 대한 미분류율 예상값 (노령층 관련된 확률로 계산)
50대 (또는 60 대) 이상의 투표자들이 후보1을 지지하였고 또한 그들의 표가 더 많이 미분류로 갔기 때문에, 미분류에서 후보1이 후보2보다 상대적으로 득표를 더 많이 했으므로 K=1.5가 되는 것이 자연스럽다고 설명하는 분들에 (특히 선관위와 SBS) 대한 답변이 되겠습니다.
먼저 노령층 가설의 논리를 요약하면 아래와 같습니다.
a) 50대 이상이면 미분류표를 더 많이 만들었다.
b) 50대 이상이면 후보1을 더 지지했다.
c) 따라서 미분류표에서 후보1의 표가 더 많이 나오는 것이 당연하다. 그래서K=1.5 가 나올 수 있다.
지난 번 가설 검증 자료에서 보여드렸듯이, 첫 번째 (a) 내용은 확인되었고 동의합니다. 다만 이 현상은 후보1뿐만 아니라 후보2에게도 나타났음을 고려해야 합니다. 또한 여론 조사에서 두 번째 (b) 내용도 대체로 뒷받침되고 있습니다. 논점은 세번째 (c) 내용에서 얼만큼이라는 분석이 빠진 채, 어떻게 K=1.5 가 되는지 설명하지 않고 대략적인 잠재적 가능성만 언급한 것입니다.
따라서 위의 논리를 아래처럼 변경하는 것이 좀더 정확한 표현일 것입니다.
a) 50대 이상이면 후보1과 후보2 지지자 모두 미분류표를 더 많이 만들었다. 이러한 현상은 지지하는 후보 또는 지역과는 상관없이 연령에 의해서만 나타나는 것을 뜻한다.
b) 50대 이상이면 후보1을 더 지지했다고 한다. 그러나 여론 조사가 가지고 있는 오류 (bias) 또는 오차 (variance) 때문에 얼만큼 더 지지했는지 수량화하기 어렵다.
c) 후보1의 후보2에 대한 비율이 미분류표에서 상대적으로 커지는 지역이 있을 수 있다. 그러나 K 는 분류표까지 고려한 값이므로, 미분류표 특성만 이용하여 K=1.5 (전국)과 251개 각 지역을 모두 설명할 수 있는지는 모른다.
지금부터 앞에서 이미 계산한 확률들을 이용하여, 노령층 가설이 18대 대선을 제대로 설명하지 못하는 한 가지 예를 보이겠습니다. 아래의 식은 미분류표 비율을 계산하는 확률식입니다:
Pr(U) = Pr (U|A) Pr(A) + Pr (U|B) Pr(B) =q*a+r*(1‐a).
여기에서 q & r 은 전적으로 연령층에 의해 결정되는 것이므로 지역마다 달라지지 않지만, 50대 이상 연령층의 비율은 각 지역마다 달라집니다. 실제로 q & r 은 전국 데이타를 모두 합하여 계산하였습니다. 예를 들어 비만도는 BMI 를 이용하여 판단하게 되는데, 그 것을 계산하는 공식이 바로 위의 확률식에 해당되고, 비만 위험=30이라는수치가 q=0.062 & r=0.018에 해당한다고 볼 수 있습니다. 다시 말하자면, 비만 위험=30을 찾기 위해서는 인종, 지역 등등 가리지 않고 모든 사람들의 자료를 근거로 하지만, 각 개인의 비만도를 판단할 때에는 개인의 키와 몸무게를 적용하게 됩니다. 따라서 위의 식을 이용하면 각 지역마다 다르게 나타난 미분류율을 설명할 수 있습니다. 이미 계산한 확률 q & r 두 가지와 각 지역의 50대 이상의 비율 (a) 251개 값을 적용하여 각 지역의 미분류율을 예상할 수 있습니다:
<더 플랜> 연구팀이 가지고 있는 50대 이상 비율을 (한국 통계청 전국 인구통계 자료 사용) q & r 확률과 함께 251개 지역에 적용한 결과가 아래 그래프에 나타나 있습니다. 예상값이 실제값과 많이 다름을 볼 수 있습니다. 이 것은 노령층 즉 연령에 따른 특성만을 가지고 251 지역에서 드러난 미분류율을 설명하는 것의 한계를 보여주는 것입니다.
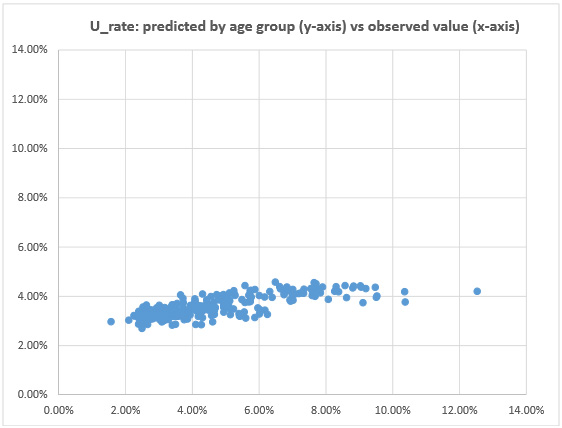
노령층 가설은 미분류표가 노령층에 의해 전적으로 만들어진다고 설명하는 것이므로, 251 개 지역에서 나타난 미분류율이 위의 식에서 나온 미분류율 예상값과 비슷해야 합니다. 아니라면 노령층으로 미분류율을 설명하지 못하는 것입니다. <더플랜> 시나리오는 후보1 과 후보2 의 득표율 네 가지를 잘 설명할 수 있는데 비해, 노령층 가설은 미분류율 한 가지도 제대로 설명하지 못하는 큰 대조를 보여줍니다.
맺음말
투표자들의 연령 분포와 특성을 가지고 분류표와 미분류표에서 나온 후보1과 후보2의 차이를 각 지역에 대해 잘 설명할 수 있다면 참으로 반가운 일입니다. 그러나 본 연구팀은 각 지역의 50대 이상 연령층의 비율을 가지고 각 지역에 대한 설명을 제대로 할 수 없었기 때문에, <더 플랜>에서 공개한 시나리오를 생각하게 되었던 것입니다. 이 시나리오에서는 18대 대선 선거 테이타만 사용하였습니다. 연령 분포 또는 특성에 대한 자료를 사용하지 않아도 전국적인 결과와 함께 251 각 지역에 대해서도 잘 설명하였습니다. 이렇게 선택한 시나리오에 대해 다양한 의견을 환영합니다만, 음모론이라고 비난하는 것은 시민 운동의 하나로 진행하는 선거 분석들을 위축시킬 수 있습니다. 공개한 시뮬레이션의 깔끔한 결과와 엑셀 화일을 면밀하게 검토한 후, 다시 판단하기를 바랍니다.
<더 플랜>에서 언급한 것처럼, 전국 대선 결과를 설명하는 방법으로 K=1.5 이외의 다른 방법도 있을 수 있겠습니다. 그러한 방법들이 찾아지기 바라는 마음으로 데이타와 시뮬레이션 코드 등등을 공개합니다. 어떤 가설 또는 방법이든, 각 지역 분류표와 미분류표에서 나온 후보1과 후보2 각각의 득표율 네 가지를 재구성할 수 있으면 환영합니다. 많은 분들의 참여와 아이디어를 기다리겠습니다.
알림:
(1) 2012 대선 다섯 가지 가설 검증에 대한 1차 자료 중 페이지 7에 잘못 표현된 곳이 있어 아래와 같이 바로 잡았습니다 (프로젴 부의 웹사이트 참고). 이러한 오류를 찾아 알려준 분께 감사드립니다. 다른 오류들을 발견하여 알려주시면 검토하겠습니다.
-> 총 251 개표 지역 중에서 두 군데를 제외하고 나머지 249지역에서 후보1 의 미분류율이 후보2보다 높게 나왔습니다 (99%). => K 값이 1보다 크게
첨부 1 18대 대선 데이타 & 시뮬레이션 결과_251 개표지역 (May01_2017).pdf
첨부 2 K_Election_2012_Prediction‐by‐K1.5_All‐251‐districts.xlsx
| 출처 | http://www.projectboo.com/archive/153432 |


 글쓰기
글쓰기